Hachi: An (Image) Search engine
Only the dead have seen the end of war .. George Santayana
For quite some time now, i have been working on and off on a fully self-hosted search engine, in hope to make it easier to search across Personal data in an end to end manner. Even as individuals, we are hoarding and generating more and more data with no end in sight. Such "personal" data is being stored from local hard-disks to corporate controlled cloud-centers which makes it distributed in nature. So for following discussion, "Personal" meaning would be flexible enough to accommodate resources on a remote server and/or on different devices, as long the user could prove authentication and/or authorization to that data.
Current implementation supports only "images", but eventual goal is also to support other modalities like video, text and audio, some code would be shared, while some new code would be required to better extract Features for each modality.
Such distributed nature of data and potential capabilities of current self-hosted Machine learning models to extract semantic information, only to be queried through a single interface seemed enticing enough for me start this experiment in the first place. Following post at times may seem in-coherent, as i try to articulate my thoughts on the journey of development, challenges faced and future ideas. I hope to treat this as a personal essay with multiple themes, anecdotes and even random thoughts aiming to provide a higher level view of the journey and philosophy so far in more concrete terms.
Also, following post doesn't aim to cover every technical choice and implementation in finer details, such discussions would instead be part of dedicated future posts!
Motivation:
As Humans we tend to remember different attributes/parts of an entity/information at different times, and most of search engines' interfaces refuse to accomodate that. User generally end up with an unidirectional flow of information, with no recourse of providing feedback to improve upon the on-going query. Even most advanced interfaces fail to handle the stochastic nature of queries and humans' pre-disposition towards partial information to keep moving, it should be default for search-engines to present best-effort suggestions for queries even if they couldn't be fully resolved.
I also note that, it is not always easy to model the imperfect information like handelling a mis-spelling, which itself could be mis-spelled in many ways. It would require a conscious effort to put in a better search interface, as most digital machines make it easy to model when "something" is "correct" or when something is "incorrect". Conveying "Why" something is incorrect takes a lot more code, effort and time, hence indicating that economic realities are more to blame for such cases than bad intentions!
It also presents an opportunity to analyze the capabilities of a good interface, as personal data would make it very easy to notice its limitations, which couldn't be observed through seemingly complete interfaces exposed by many e-commerce companies.
Inspired by above stated ideas, My try has been to expose multiple (if not all) attributes for a resource directly to user and then letting user recursively refine query to get to desired result. Implementation is still far from complete, but this theme has served me well to set a basic roadmap for the project. Other themes such as self-hosting, hostile behaviour towards users in terms of privacy-invading features, limited or no options to refine a search by google, github etc has contributed to evolution of this experiment. Distributed queries being served by a cluster of (refurbished) smart-phones or single-board-computers remains a lofty goal of this experiment too!
Despite all the good intentions and ideas, any search interface should pass that threshold of being fast enough to not end up as another impractical experiment. Efforts were involved from the beginning to embrace the inevitable complexity such projects come to include despite many refactorings. Below is a minimal video to help visualize the current state and capabilities of the project.
Broader Ideas:
-
Minimalism: Minimalism in terms of number of external dependencies required for this project to be bootstraped, could explain a lot about downstream choices and evolution of the project to its current form. This has of any existing (source) code if possible or writing it from scratch which itself would require reading of a lot of existing code before i could port it to extend the project in a pure source sense. If it would be practical to reuse some code from existing capable projects/databases, i would have done so but most of such projects are designed to be de-coupled from application code for good reasons, as they are supposed to offer much more guarantees and stay robust even under heavy load. Being an (embedded) part of personal application we can choose to do away with such guarantees and yet expose much more information by tightly integrating ML models pipeline. In the end, application would handle much more complex indexing and inferencing pipelines, which would require a lot more code apart from search and storage interface generally expose!
-
Experimentation: Thinking more about in terms of augmenting the existing information, rather than to duplicate it, while fusing traditional (deterministic) attributes with semantic(ML) attributes. I think this is an interesting problem and which have not been fully utilized/explored for personal applications. Most of traditional databases were written to only handle "text" modality, but current ML models allow us to query semantic information too, which opens up a new space to experiment in. I treat semantic information as necessary and independent, but not the only signal useful to implement great search interfaces.
-
Hackability: For this project i wanted it be very easy for someone to start modifying it according to their needs, and this mostly co-relates with the first point about minimalism, lesser the number of dependencies, lesser is the amount of configuration required to bootstrap the developing environment. Both Python and Nim are stable, cross-platform languages and are easier to extend just using a C compiler. Nim source code it easy to compile and/or cross-compile to on almost all platforms. There are already python bridges for many languages, so all such languages are fair game to extend the codebase in any desired way!
Python environments (in)famously have the reputation of being difficult to bootstrap, whole parallel ecosystem is there to do so which itself creates another dependency. But i think project has made great progress in this regard, with now having a requirement of just 3 dependencies asnumpy,regexandmarkupsafeand optionallyrequests, with no hard-dependence on versioning. Almost all python environments could be used to run the project with no changes, which also removes any need to bootstrap dev environment using Docker like huge dependency or any complex unwarranted build-systems plaguing many of the interesting projects. If i had money, i would pay someone to just make such projects easier to install and start with, by removing any redundant configuration or making it possible to use one common build-system !
Even though above ideas may seem worthy to follow on, there is always an on-going fight to prevent dilution of agreed upon principals. Counter-intuitively i think there is some kind of activation-enery (https://en.wikipedia.org/wiki/Activation_energy) requirement for each project, past that it actually is much easier to extend, modify, optimize the codebase somewhat like paying a debt to live debt free:)
There are already very capable projects like Sqlite, Lucene offering full-text search capabilities, but they implement their own storage backends which require all data to be transformed to the compatible format which leads to duplication of data . This is something i wanted to avoid, as we would be continuously transforming every newer data and this would become computationally expensive when such data wouldn't even reside on same physical machine/node. If we could get away with fast-enough queries through a much simpler index/database, that seems like something worthy to pursue further.
Most of such projects were created to handle only text queries, But current ML models expose semantic information through "vectors" or "embeddings", generated after a series of linear and non-linear operations on some text or/and an image. Top-k matching results are later retrived through a "Comparison" procedure with user query (embedding) as one of inputs.
Such extensions are being gradually added in many older engines, so a hackable codebase like this project may offer more flexibilities while accomodating future ideas in this rapidly evolving field!
It leads to a design comprising a meta-data indexing engine, coupled with vector-search engines for semantic search. We never intend to duplicate the original-data and don't care where it actually resides, once indexing is done. As i think search is more about reaching to a desired file/resource before that resource could be used! Pin-pointing that resource location quickly is the major motivation by incorporating the user intentions and context recursively!
(C)Python is used as the major language for backend and Nim (and C) is used to speed up the bottleneck portions of the codebase where-ever warranted. Writing from scratch allows me to update the api as i fit to handle a bottleneck portion of the pipeline (querying or indexing), without asking or waiting for a change in some upstream dependency. Nim itself is a language with relatively smaller community, so i am getting a bit comfortable porting code from other languages to my projects with only standard library and even experimenting with my own data-structures based on (protected) reference semantics than default value semantics that Nim use!
Meta-Index:
Its a minimal module/database to handle (store and query) meta-data being extracted from resources(images) and has been written in Nim. Currently it is single-threaded, column-oriented database using Json as data-exchange mechanism between python and Nim. In future idea is to shift to leveraging multiple threads for workloads/size greater than a threshold, to better use the current hardware capabilities. It is possible to generate an auxilary index to speed up queries for a column/attribute on demand, which internally would use cache-friendly and hierichal data-structures to achieve so for most of scenarios!
Through development of this module, it has been easier to note that why most of databases end-up with some kind of dedicated query language, as situations arise requiring composing multiple operations in one go which seems like a cleaner way to model such intentions. (and this also seems to validate the requirement of a query-planner to better execute a query by analyzing the order and nature of operations and some internal details).
Since it would be written for hachi itself, it remains possible for me to speed up a frequent operation by sharing a pointer/memory directly across Nim and python to prevent costly copy operations, or to directly serve raw json to the frontend in some cases without serializing and de-serializing at python boundary.
I have also experimented with multi-versioning storage design as Lmdb, to protect the original information created by code itself from user revisions. But current implementation instead favours creation of a dedicated field/attribute for user to modify/update.
For example during face clustering process, backend will assign an unique Id for each new cluster, to which user may want to change to a more descriptive name, this leads to presence of attributes like personML and person in the final schema. By default, any attribute/information generated through during indexing pipeline is supposed to be immutable to be easily reset to genesis state.
It still is a bit rigid implementation, as schema is locked once initialized (lazily or explicit), as adding new columns dynamically will require me to reallocate data in the memory and more syncing logic which i am off-putting for now and will work on in the future!
Current iteration supports string, int32, float32, bool, array[string] data-types, which seems to be enough for the application needs, but could be evolved in the future. I am not particularly content with current "string" querying, one reason is that Nim by default does not have a concept of no-copy slice, and it is difficult to even expose such a user-defined type. As strings are null-terminated, so most of other composed data-structures with string as one of fields have that underlying assumption which that user-defined type will break. Also i think for a lot of meta-data attributes, i could use ShortString kind of data-type to speed up scanning/querying by better leveraging the cache. Some of these issues are being experimented through an independent project and if found to improve performance could be implemented in this codebase too!
There are also Simd opportunities inside the "querying" code, but since its design is being guided by overall needs for the product itself, i hope to add those architecture specific optimizations only after system-design becomes stable enough for most of the features supposed to be supported!
Face-Recognition:
Being able to group same person(s) with a high probability, as another attribute to search for or mix with other attributes, would be a very quality addition to any search interface. Current DL models for some-time now have been able to distinguish faces with a high accuracy. But being able to distinguish real-life faces still requires a conformance to the pipeline such models would have been trained with.
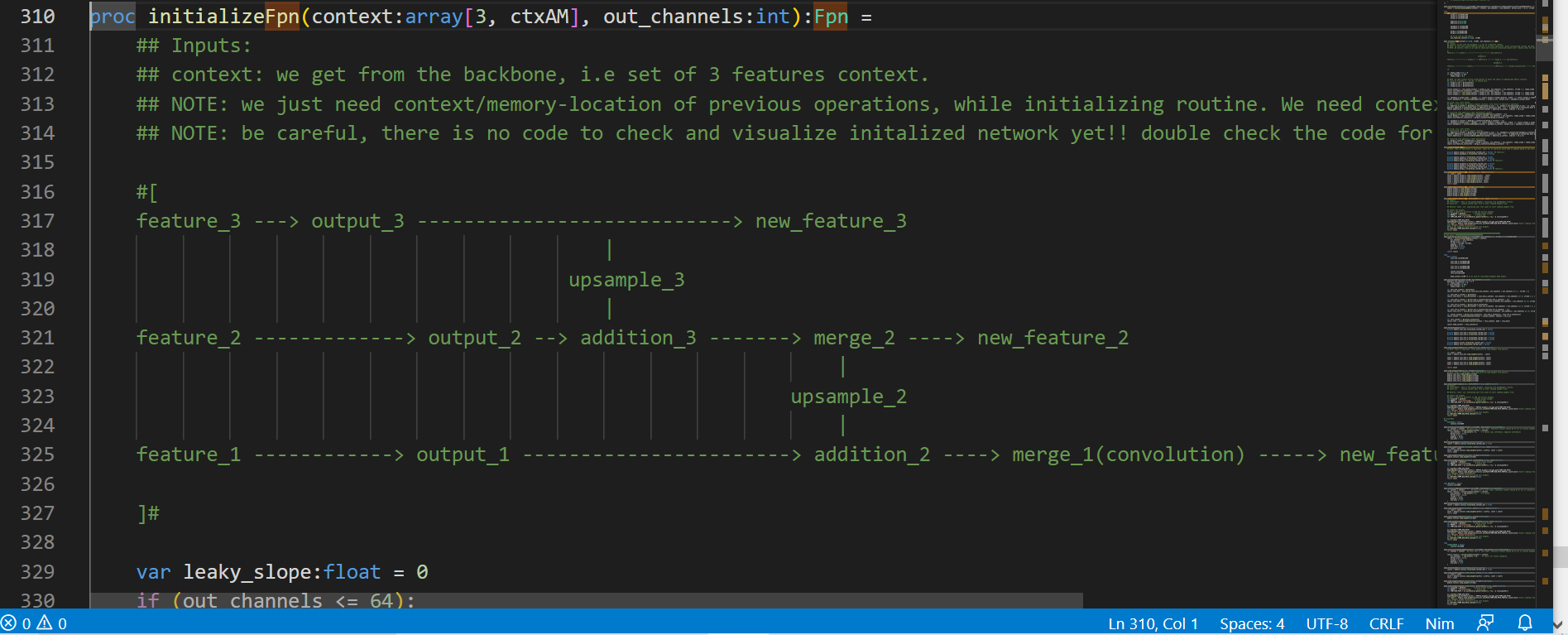
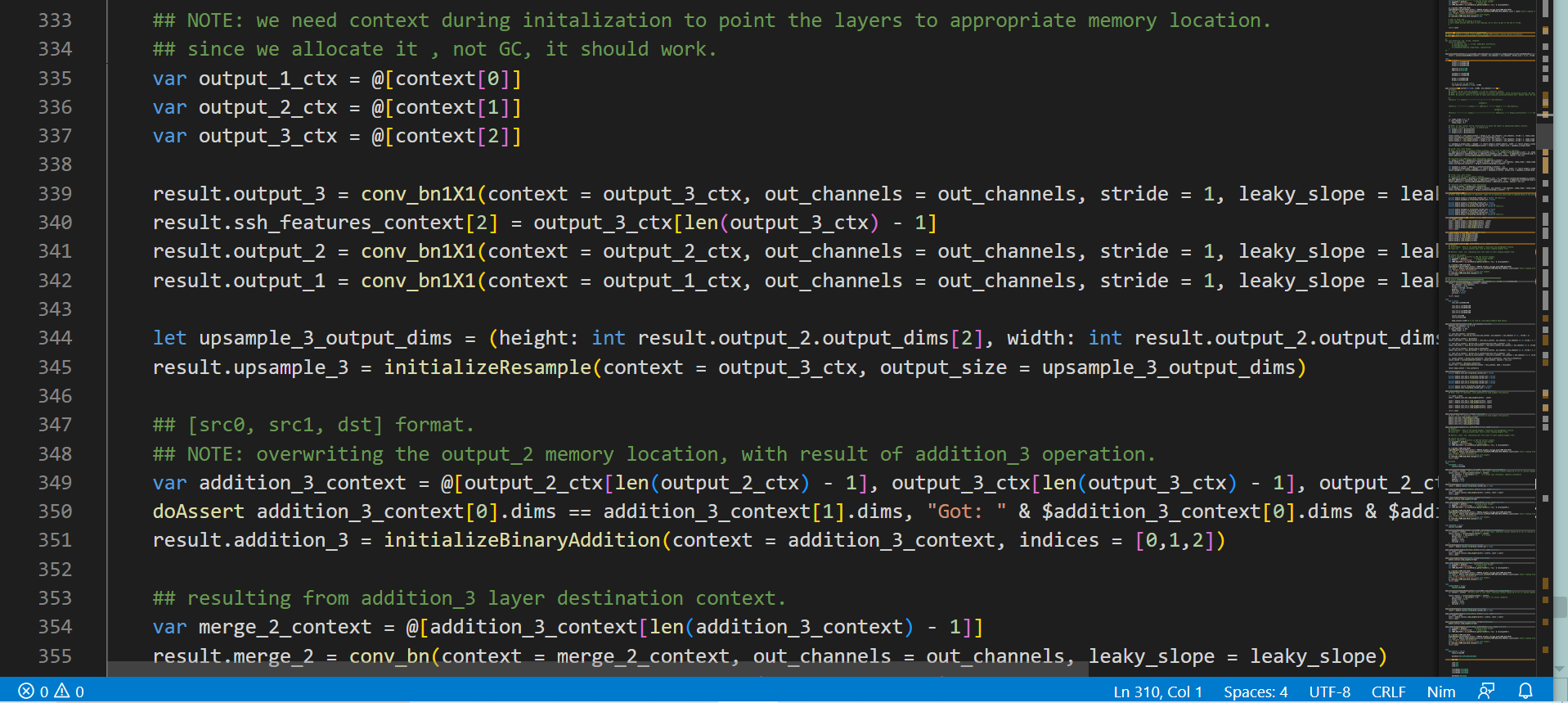
There are multiple architectures for such models that have been proposed to tackle this problem, but most pipelines could be assumed to follow a generic flow, which begins with detection of facial bounding boxes from a given image or camera frame, then followed by detection of facial-landmarks for each such face, and ends with generation of embeddings/vectors which figuratively would represent some kind of latent representation of that face. At this point, this would be reduced to a Vector Spaces problem and hence much easier to deal with traditional tools like nearest neighbour search !
It almost always overwhelming to decide on a particular Implementation to build upon, while accommodating various factors like latency, accuracy , hardware requirements, and most of such intensive pro-bono work would never even be visible to the end-user. For me atleast this goes much further, as i would be implementing each such model using an independent ML framework, which would require me to understand also all the pre-processing and post-processing code, to be faithfully ported to Nim.
Spending time on reading papers and existing implementations helps me to get an idea about overall "capability" of the model and potential requirements during fine-tuning of the model in future. Sometimes it has been enough for me to come across an interesting concept through a paper or some nice optimization trick, even if i end up not using that particular implementation.
Most of face embeddings generation models are trained on a Siamese-loss like objective to try to explicitly distinguish both positive-positive and positive-negative pairs. This generally involves manually collecting such pairs and hence prone to bias ! Such features predictors are also very sensitive to face-alignment code used, and hence may require you to faithfully follow the training code!
Dataset being used for training and choice of the objective function are two very major factors influencing the performance of any model. Leakage of evaluation data into training set has been a real issue in recent years for many experiments. Face-recognition itself is a very subjective problem and generally require more "visual" testing apart from (mathematical) metrics proposed for this problem/sub-domain.
Current pipeline uses retina-face model to predict faces and landmarks in one go which helps producing stable facial-landmarks and speeding up the pipeline. (As predicting facial-landmarks would be much cheaper from internal features than through a dedicated model, and it also helps stabilizing the training of the model).
Though it could make sense to argue about a model's ability to internalize learning correlated features without adding an explicit loss, but in practice it is always (very) beneficial to use multiple losses explicitly.
Interestingly, residual connection in ResNets was an important innovation making it possible to train much deeper networks at that time, even though it would be just mimicing an identity function.
In my experience, dataset being used for training and choice of the objective function are two very major factors influencing the performance of your model on real-life (bit out-of-distribution datasets). I find it a good practice to always visually debug some of the random samples to get a "feel" for the dataset!
Even after having a good pipeline to generate "embeddings" for a face, clustering remains a very challenging problem, due to various reasons.
Like with almost all clustering algorithms, we start out with no prior information about of the underlying (number) distribution of the data (faces). (as this is what we would be trying to estimate). As we keep encountering the newer information, possible updates through back-filling are required for the underlying index, which somewhat resembles of an auto-regressive operation and hence the error-accumulation rate is relatively high. We would also need to wait for some "initial" amount of data/information to be collected, to estimate initial stable centroids. This difficulty is further compounded by the choices for various thresholds like face-detection, some measure for blurness in the detected face, and a dependence on order of information being encountered.
As indicated, choosing same model to predict landmarks and face-bounding boxes, helps reduce the impedance mismatch that occurs when output of one model is being fed through another model. We would need to a dedicate model for facial-features though as earlier features may not be dense enough to distinguish among individual faces!
Currently Implementation works by collecting some minimal amount of information before Cluster creation process could begin.
Each Cluster is a union of a set of main/master embeddings and a set of follower/slave embeddings. Selection of main embeddings is a crucial part to maintain the stability of a cluster even when new information would be encountered. Initial filtering of unfeasible (master) embeddings is done through some static criterias, for example we strive to filter any of blurred faces, face-profile is estimated through facial-landmarks, stable forward-facing profiles make face-alignment easier further in the pipeline. Such (static) criterias definitely help to reduce the number of invalid candidates, but may not be enough for many real-life datasets. A further minimal module comparing the hog-features with a set of pre-saved hog-features is introduced to help invalidate faces with sunglasses and some false positives not caught by earlier criterias!
no-categorical-info, when not able to being fit into any of the clusters.
Note that a lot of empirical data comes into effect as multiple decisions would be required while choosing many thresholds and may require multiple runs .
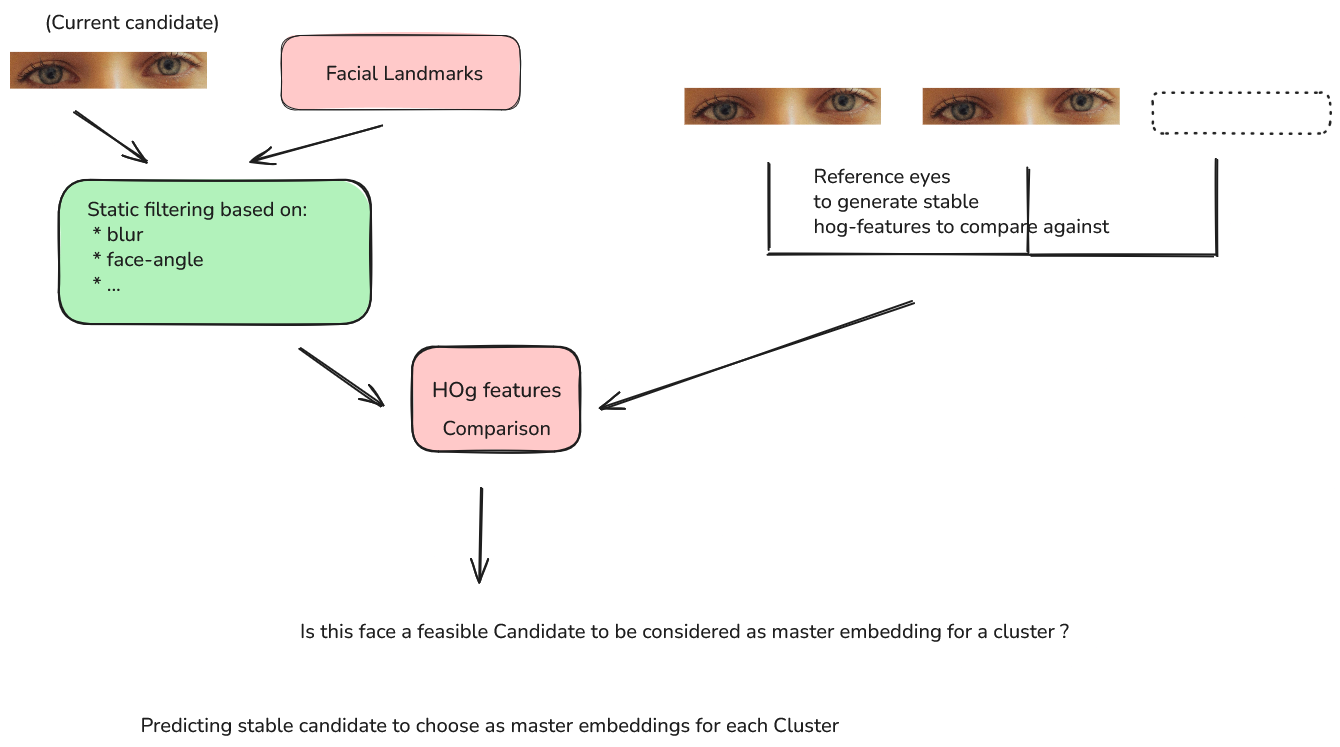
Since face-recognition is very subjective and i myself have to compare other features to make sure that indeed the correct person(s) have been grouped together by the pipeline. But with a latency of around 25 ms, it seems to do very good on a held out dataset of persons with close up faces, (Zen-Z) selfies and sunglasses occluded eyes. Personal photos are much easier to classify/recognize compared to such a dataset!
For any practical ML integrated product, We would need to have a very performant concurrent pipeline to keep feeding the model while being constantly aware of any data-distribution impedance mismatch, to reach anywhere near the 'accuracy' and speed promised in a research paper. This touches upon the issue of having good understanding of software engineering basics, while being aware of possible regressions resulting from a newer functionality like ML.
Though bigger VLM/LLM (base) models have potential to handle data-impedance mismatch issues due to their sheer size, their usage would definitely hamper the application responsiveness and have proven to be relatively rigid to be fine-tuned for a specific domain!
Indexing:
Indexing pipeline begins with desired data location as its input to recursively scanning directories to collect raw-data in batches.
Multiple meta attributes such as exif-data, size, mount location, name are extracted to be later queried through the Meta-indexing engine. Focus has been on designing a good schema to accomodate future use-cases, but since we would be collecting only meta-information without ever modifying the original or duplicating the original data, it remains relatively easier to shift to a newer version/schema even through automatic means.
ML models extract semantic information which can be later queried through a vector-indexing engine. By default resources to be indexed are assumed to be residing on a local-disk but any protocol could be leveraged, if proper authorization and authentication could be provided.
Monolithic nature of the code helps me to share raw-data read/collected once for various components like hash generation, preprocessing code for ML models, reducing the number of costly I/O calls. This pipeline has come a long way from a blocking implementation to its current (almost) fully async nature, resulting in very high saturation of computing resources. Apart from running multiple threads, dedicated kernels/functions are used to speed up pipeline by fusion of operations wherever possible.
One such example/scenario has been shown below.
def preprocess_kernel(
image:Tensor[uint8],
new_shape:tuple[int,int],
rgb_to_bgr:bool = True,
normalize:bool = True):
# Preprocess kernel, may fuse resize, color_conversion and normalization into one function!
# Pseudo-code!
result = newEmptyTensor[uint8](new_shape)
for i in new_height:
for j in new_width:
inp_h, inp_w = get_corresponding_pixel(image, i, j)
for k in 0..<3:
if rgb_to_bgr:
result[i,j , 3-k-1] = image[inp_h, inp_w, k]
# normalize based on mean and deviation used for training dataset further...
else:
result[ i,j,k] = image[inp_h, inp_w, k]
Each resource could be assumed to go through a flow like this:
resource_location = "file://xyz.jpg"
# OR
resource_location = "remoteProtocol://xyz.jpg"
raw_data = download_raw_data(resource_location)
embeddings = ML_model( preprocess(raw_data))
exif_data = extract_exif_data(raw_data)
preview = generate_preview(raw_data)
write_preview(preview)
....
Vector Index:
It is another minimal module to store vector-embeddings as shards on the disk. Necessary meta-data is stashed along with that shard, to make it self-contained, which in future will help in distributed/parallel retrieval. For now each shard is just a numpy (float32) Tensor, and comparison routine is a np.dot operator, which itself use the blas/openblas library to speed up this operation! Each shard is loaded from the Disk during a query, and top-k candidates are collected to be fused together with other deterministic meta-attributes. Loading from Disk do add some latency, but it allows me to regulate RAM usage through shard-size hyper-parameter, to allow running this on different platforms with diverse specifications including single-board computers. Shard-size could be kept relatively high for higher RAM systems to speed up shard querying.
Matmul is one of the most optimized algorithms which run at almost 90% of theoretical capacity on most of intel/amd Cpus when leveraging Blas like libraries. So every further optimization from here-on would involve some kind of information loss. There is a whole literature now to speed up this comparison/retrieval process through quantization and/or nearest neighbour indices like HNSW. Fast SSDs are also leveraged to run such comparisons at very high speed for upto billion vectors on just a single node in near real time!
But such all techniques involve compression of information (which itself is best-effort being the result of modeling a large amount of biased data) through out-of-band mechanisms, for example creating centroids/clusters is just based on the vector values and taking some mean without a way to pass back the information to the model which produced those vectors in the first place. This way is quick and you would get great speed-ups, and there is an active debate among vector-database vendors across various metrics and implementations. In my experience only visual results on a personal data would be a good metric a user should test for. Product-quantization is something i would be implementing if were to choose one, as i think coupled with top-k, it should work reasonably well to include (subjectively) correct results (high recall!) .
Another worthy and very effective solution i think is to instead train a linear layer to finetune the original model depending upon the task. ML Features/embeddings from a big enough model, could assumed to have a knowledge about diverse topics, but for example, a user may be trying to distinguish between different plants. A linear layer could easily be trained with just few thousand samples, to achieve so with much higher accuracy than original models, and even with half the size/dimension of original embeddings. Intuitively it could be thought that we freed the information channels to just focus on plants, decreasing the entropy model earlier had to deal with. Any such layer could be trained even without any framework, as it would just be one backward operation to implement.
OpenAI has a nice cookbook if a reader would want to explore this further!
https://github.com/openai/openai-cookbook/blob/main/examples/Fine-tuned_classification.ipynb
An interesting thing sharding allows is to use any available hardware to speed up retrieval. Since we need just comparison routine and corresponding shard(s) to return top-k candidates, it de-couples it from any of application code. A new smartphone could be detected, and some shards could be transferred during initial set-up, optimal percentage/number of shards could be easily calculated by running same comparsion operation on new device. Like running a 2048 x 2048 , inner-product op and comparing latency with master/main device, would tell us the capacity of the new device and so that number of shards would be transferred to speed up retrieval process!
There are performance gains to be have in the current implementation, would like to atleast start using float16 data-type, but its a bit tricky on intel cpus with no compiler support for this type. Printing of CPU capabilities do show the presence of float16 hardware support on my system !
ARM(v8 64) seems to offer native float16/floatH types, there seems to be difference in that type either supported natively by compiler or as an intrinsics/assembly code. I have not been able to get expected speed up for now! Such code is still being experimented upon in the limited time i have.
Backend:
Backend is written in python, which exposes a pure API server, to let the client/frontend to make API calls to. Starting with very naive code to just return all the meta-data for a directory to current pagination support it have gone through many revisions and design iterations and now i have much clearer idea about how to architect/wrap a big enough piece of functionality. I wanted the app to be end to end, but this also put extra pressure on app to be responsive enough for all user events. Current indexing code is capable of providing rich details such as directory currently being scanned, estimated time (eta) and allows robust Cancellation of an ongoing task/threads.
It has not been easy to model such communication b/w concurrent tasks and touches upon much discussed structured-concurrency debate i.e how to run multiple tasks asynchronously, while being able to robustly cancel them at any point in time, all while being able to collect all errors cleanly!
From C days, i have been a user of (Posix) threads type implementations, since major OSes provide those minimal but stable APIs, it helps me during context switching to different languages. Both C and Nim expose that, Python itself let the OS manage threads without its own runtime implementation, but bypassing the GIL when makes sense is something user have to do to fully utilize the resources! Also this kind of code requires user to handle a lot of code as to communicate b/w threads but atleast i (think) understand the basic ideas to prevent deadlocking if occurs and iron out initial bugs. As you run such threads deeper and deeper inside application stack , it keeps getting harder to communicate information back to the client. But when it starts working, it is really cool to have a central interface to see all the stuff backend is doing and predict very good ETA !
Flask was initially used to easily map functions to a particular route/url to wrap up initial implementation, current implementation now just uses werkzeug (main engine behind flask) directly, hence doing away with a lot of unrequired dependencies like a template engines that Flask ships with. Even though this would not effect the end user in any visible way, this has been a very nice quality-of-life improvement like stuff for me as a developer. Since werkzeug is pure python, it can now be shipped/bundled directly as source code. Also each request is now handled by an available thread (from a pool) by reading http environment from a shared queue following conventional model. By default for multi-threaded option, werkzeug would create a new fresh thread for handling that request. This does away with lots of OS/system calls for each new request and latency now seems more consistent and predictive. I have also stumbled upon a pattern to actually make it easier to mount multiple apps cleanly given i never liked and even understood the blueprint that flask offers to make it easier to distribute the logic of your app to other modules too.
Since WSGI protocol just expect a callable python object, it should be much easier to develop independent apps without having any knowledge where it would be called/used. It also makes it quite fun to actually write/expose python code to handle client inputs.
class SimpleApp():
"""Each instance could be used a WSGI compatible callable"""
def __init__(self, allow_local_cors:bool = False):
self.initialized = False
self.http_methods = ["GET", "POST", "PUT", "DELETE", "OPTIONS"]
self.url_map = None # we will lazily initialize it!
self.extension_prefix = "ext" # as apps would be registered/
self.registered_extensions:dict[str, SimpleApp] = {}
....
def add_url_rule(self
rule:str,
view_function:Callable, # corresponding view.
endpoint:Optional[str] = None, # set to view_function
methods:list[str]= ["GET"]):
... # some validation code.
self.endpoint_2_uri[endpoint] = (Rule
(rule, endpoint = endpoint), methods
)
self.endpoint_2_viewFunction[endpoint] = view_function
self.initialized = False
def register(self, app:SimpleApp, name:str):
"""
Here we register another such `app`.
It would be mounted at `/ext/<name>` , so all requests to /ext/<name>/<route>, would be forwarded to this `app` .
"""
... # some validation code.
self.registered_extensions[name] = app
print("Extension registered at: {}/{}".format(self.extension_prefix, name))
def __call__(self, environ, start_response) -> Iterable[bytes]:
# This is called
if not (self.initialized):
print("[Initializing]: Parent")
self.initialize()
for ext in self.registered_extensions:
if not (self.registered_extensions[ext].initialized):
print("[Initializing]: {}".format(ext))
self.registered_extensions[ext].initialize()
# If a call to such an extension.. we modify the environment a bit.
active_app = self
extension_name = None
temp_path = environ['PATH_INFO']
temp_split = temp_path.split("/")
if temp_split[1] == self.extension_prefix:
extension_name = temp_split[2]
assert extension_name in self.registered_extensions,
extension_path = temp_path.replace("/{}/{}".format(self.extension_prefix, extension_name), "")
environ['PATH_INFO'] = extension_path
environ['REQUEST_URI'] = extension_path
environ['RAW_URI'] = extension_path
active_app = self.registered_extensions[extension_name]
## -----------------------------------------------
# NOTE: only werkzeug specific code is here!
# ---------------------------------------------
request = Request(environ = environ) # minimal wrapping code!
urls = active_app.url_map.bind_to_environ(environ)
endpoint, args = urls.match()
# view function can choose to return iterable[bytes] are the result of view function or call , or further wrap it to be as expected by werkzeug!
iterable_bytes = active_app.endpoint_2_viewFunction[endpoint](request, **args)
return iterable_bytes # as WSGI protocol expects!
# ---------------------------------------------------------
Note that, any existing Python object, can be made to accept client requests on demand by adding very minimal code and could be done for selective functionality. For example, during setup of a new android device, i may have to ask user to choose one of the existing devices, this kind of interactive input can be modeled easily now, as i just add a new routine in the Corresponding class to accept requests on a route such as /ext/android/beginSetup, once i get that, all the existing logic already written could be used to finish setup. It is as easy as parent_app.register(app = thisApp, name = "android") to start routing corresponding requests to this app!
ML:
Machine learning is being powered by a framework written completely in Nim, most of work was done on that framework before i even stared working on this project. This has allowed me to wrap CLIP and Face-Recognition Pipeline along with the application while only depending on OneDNN for some routines. OneDNN (mkldnn) (https://github.com/uxlfoundation/oneDNN) is one of the libraries to speed up various Deep learning operations with great documentation.
Ported models run faster on intel/Amd Cpus than pytorch counterparts, owing to fusion of operations like Batch Normalization and Convolution, and high re-use of pre-allocated memory (similar to in-place operations). Current torch.compile like engine would end up making some of those optimizations after analyzing the graph, but for at-least 2.0 version it is not supported on Windows for me to compare against!
It took a lot of effort during one-two years i was working on it to be complete enough for me to start porting Deep-learning models using it. Also OneDNN shifted to V3 during that time, and only some code was updated to newer API and this has left the project in a unstable state with no visible stable APIs for users to work with. For each model i have to manually analyze the locations/requirements for fusion of operations, port quite a lot of pre-processing and post-processing code to make it end to end. These reasons contributed to a lot of technical debt, which i have not found the resources to tackle yet. Without removing that debt it never made sense to open-source it, besides there are now projects like GGML, and tiny-grad to serve inference only needs with minimal resources!
Porting of each model is quite an involved task, as you have to read enough papers to understand ideas about model if want to later fine-tune that model too. You may want to find first find or create a simpler implementation in pytorch to make it easier to port to a new language. All experimentation could be done in pytorch/python, for example i experimented with alternate quantized attention layers for CLIP model, and it indeed had a better performance for eval datasets mentioned in CLIP paper. Tangentially it was really cool to read through Open-AI implementations and papers, papers were written in an approachable manner to let the read indulge in hypothesis, codebases were clean with minimal dependencies. Its really a shame what that company/organisation chose to become under the guise of "user-safety" effectively clipping the (open) ethos of this field, but at same time i am grateful for all the researchers' work in this current DL/ML era and seeing the evolution of this field in such an open manner!
I would like to work on the project though atleast enough to tackle that debt and open-source it in state for users to extend upon, if found useful. Even though i am using OneDNN for some routines, i think it is better to have a common and easier to extend codebase to allow more experimentation and aggressive optimizations , but this itself is a huge-task and now with multiple GPU architectures its just something that couldn't be tackled without a lot of time and money. Even in this age where H100 is the baseline for benchmarks in testing, i find it worthwhile to work on a minimal DL Compiler to just tackle ARM/Intel/Risc Cpus to start taking advantage of these cheaper machines. Being able to pin-point a tennis ball in a 3D space remains the dream !
Frontend / App:
Current front-end is completely written in Html, Js(Ts) and (tailwind) css as multi page webapp. Earlier frontend was written in Svelte, but lack of internal documentation and too much "magic" became too "viral" for me to handle. For me, abstractions and APIs exposed by Browsers are more than enough to maintain required precision during DOM updates. Care is taken to use batch updates, prevent redundant rendering, judicial usage of resources to prevent unrequired pressure through pagination, even for a local backend server. It has passed our litmus test for search over 180 Gb of indexed Pexels dataset on a (minimal) remote server. My friend Akshay helped a lot in frontend development, testing various datasets and offering detailed bug reports which helped uncover a lot of edge cases during development of the project. There would always be room for improvements on the UX/UI side, but we have found it is much easier to extend and improve frontend with a stable backend!
Pexels dataset: https://huggingface.co/datasets/opendiffusionai/pexels-photos-janpf
Apart from webapp, there is also a Windows App, which under the hood uses the webview to render the frontend. All native Windows APIs remain available to use from the Nim code, which puts it into a hybrid category. It is not ideal, but atleast it doesn't require me to ship a full web-browser, which i think is waste of compute resources, but at the same time leaves me wondering how current GUI development became so resource intensive for a single developer to manage while offering little benefits! I have been looking into forks of earlier GTK versions for linux to keep the complexity/learning contained, but that also seems nothing less than an adventure!
Tools/libraries:
-
Nimpy (https://github.com/yglukhov/nimpy) : A minimal python-Nim bridge to make it easier to write extensions in Nim to be called from python and to use python modules in Nim. Unlike many such bridges which includes a lot of boiler-plate code, there are no complex classes/interfaces to be included in the extension. It targets necessary features like marshaling of native python types to and from Nim, targets the minimal Python API to not depend on python versions, finding underlying python.dll at runtime.
-
Stb Image (https://github.com/nothings/stb): A big fan of such single header libraries, this one implements encoders for most of image formats in pure C. Its very easy to modify it pass pointer to the raw-data and writing raw-data to a pre-allocated memory saving costly memory copying particularly visible for 4k photos! It helps remove dependency on OpenCV for image reading ! Nim made it very easy to just compile this along with other Nim code.
-
LibWebp (https://github.com/webmproject/libwebp): Allows decoding and encoding for webp formats, Though documentation is a bit sparse on some internal API usage, lot of examples are included in the repository to read. I managed to use
argbfield directly to passargbformat data to do away with transformation logic and some (memory) allocations. It follows callback passing convention to implement custom behaviour like a progress bar and to write encoded data to a user provided buffer. Written completely in C and very easy to compile and read, it is being used for writing image previews, helping remove dependency on OpenCV. -
Zig-cc (https://ziglang.org): Using
zig/clangas a C compiler, allowed me to easily cross-compile a lot of Nim code for Linux, targeting2.27 libc. Making it easier to set a LibC target has proved very useful to bypass thatlibCmismatching stuff! Really cool work by Zig community to tackle a lot of such technical debt to make software development much easier !
As mentioned earlier i try to use a lot of existing open-source code if i can, even it would be for reading/understanding purposes only. It still blows my mind even after many years, to just read/understand some complex implementation and modify it for personal use-case for Free.
For example even though OpenCV is a big/complex dependency, its still has a very readable codebase and i read code from it a few times during this project to understand differences b/w my port and OpenCV one.
Being able to integrate multiple languages has its own challenges too, as it would require us to understand boundaries, internal details, assumptions that each runtime would want developer to respect. It gets complex to reproduce and understand bugs while running multiple multi-threaded runtimes as debugging gets more difficult. Debugging is one of things i would like to get better at, i have very limited knowledge of GDB as of now, which is expected to be table stakes for debugging in such environments. I have had some nasty bugs , but being able to compile all required pieces made it a bit easier to debug even with print-style debugging :)
Current State:
A lot of functionality is working, than not and having tested over 500k images i could be a bit satisfied about internals' performance and robustness. I would like to say that it can easily handle 10 millions of images/resources, and there is nothing to suggest that it won't, but it is different from using a production database to extrapolate the performance confidently. Despite writing from (almost) scratch in a number of languages, both indexing and inferencing pipeline are more expressive, robust and faster than many similar images search apps, but benchmarking for such complex apps could be subjective and more so when you mix in semantic search.
There are still some hardcoded constants and also intentionally some low performing components, like using ViT B/32 variant of CLIP model, which are acting as placeholders, and would be replaced easily with better counterparts in the future.
It has been tested on Windows 10/11 and on Fedora 42/43 with an assumption of x64 architecture. Compiled extensions are also packaged to quickly test the application, but users are free to compile code as they see fit. Linux shared objects target LibC 2.27, so should work on most of recent distributions out of the box. Except some ML code there is main requirement of any/a C compiler to further extend the codebase by the user. Most of testing is done on my Laptop with i5-8300H processor and 8 GB memory. I don't have a MacOS to test on, ML code would need to be modified to target ARM architecture, except that very minor modifications should be needed if any. It is quite possible for initial users to encounter minor bugs, due to its limited run in diverse dev environments, but installation and usage on Cloud servers during testing has been quite smooth.
Below is a video showcasing workflow to index data from multiple MTP/Android devices. (Still a WIP).
Random Thoughts/Philosophy:
I think it gets easier with time to grok larger codebases to isolate/find the functionality/implementation reader would be interested in. Most of mature codebases are organized to help navigating the source-tree anyway, and have detailed documentation. Being able to have enough patience to make yourself comfortable is a necessary part of growing as a developer, as initial documentation/codebase would always seem alien and big enough to trigger that flight reaction!
Batching and Caching are two generic strategies that could be applied to speed up most of bottleneck portions. Both strategies lead to better/denser utilization of CPUs by (trying to) minimise the costly load/store instructions during a hot loop. Batching for example could do it by allocating necessary memory up-front for a batch and de-allocating all at once when no longer required, reducing the number of costly system-calls. Caching may involve designing or using a (hardware)cache friendly data-structure, when it is possible to do so.
Each optimization would involve assumptions and each subsequent optimization would become harder and harder to implement, may preventing the clean refactoring of code when future functionalities may need to be accommodated. It itself is a kind of rabbit-hole, and user should know when to stop as there would always be something else to be optimized!
With (coding) tools involving AI/LLMs it is easier than ever to get a piece of desired functionality, as a developer i understand it is another useful tool in a long-history of improvements, that most of developers would come to use in their workflow. Current LLMs have undeniable ability to handle complex instructions, explain non-trivial code and that so for various mixed modalities! It has been a bit unreasonable to end up with such abilities with just next token prediction as primary objective, even for a researcher working in this field.
My usage for such tools is only through a (free) search engine(s), Although for now there has been no scenario in such tools have helped me, that i wouldn't have got to using traditional means. But i can admit such tools/engines are really effective in helping us to get unstuck in a variety of situations, arguably helping us to learn faster. Functions/routines are nice and enough abstractions to provide enough context to such engines, to get the required help, without ever needing review/edit/rewrite cycle.
I have always been benefited from visiting the original documentation, if AI is spitting out good enough arguments, there must be a good documentation out there for that topic . Our minds capability to extract abstract patterns resulted from studying one topic and applying it to another seemingly unrelated domain is uncanny to say the least. Also tone/motivation for developer writing about a topic matters to me, and many times i have visited a concept further just because writer himself/herself was very excited about it . Again, these are just personal factors and biases and people should be free to choose workflow they feel most comfortable in , without any judgments from either side.
It has been difficult to access SOTA models actual abilities, with fewer and fewer details being published for each newer version, but it has been a wild-ride for me to see the evolution from RNNs to bi-directional RNNs to LSTMs to Transformer architecture (finally founding atleast one stable architecture be able to support training on whole internet without exploding or vanishing gradients).
Arguably there are also more more open family of models like Qwen or Deepseek from other labs which could run on local infrastructure. Even at this stage, ideas behind LLMs are simple enough for anybody to understand without burdening them with terms like AGI . There is already great work from OLMO and Smollm to build upon and start with, for personal needs, without spending a lot of money. On technical front there is still much more to explore and it comes down to doing more experiments by smaller companies to prevent ending up with another monopoly/duopoly in this field only to later blame such for their incompetence!
I literally have no idea what would be the end game with this ever increasing ability of AI models and what social consequences we would end up with in an already fragmented and struggling world.
But it would be a mistake to abandon learning, however inconvenient it may seem at any time, if we were to survive !
Thing that really boils my blood is these (AI) companies lawless laundering of all the open-source code, art, poetry without any attribution only to be packaged as a product for users to pay for. Constant attacks on all the infrastructure even run by very small or single-developer companies/communities, not respecting any of the robots.txt, proxying through residential networks, damaging the very core of the information-sharing/internet while coming up with ironical headlines is bordering on criminal-behaviour for me! Waiting for tens of seconds just for a (community written) stack-overflow post through many layers of security, for wanting to understand various perspectives for some concept without all the bullshit summarization, is new bleak reality with nothing for end-users to have a say in.
Despite the dominant usage of LLMs there exist equally interesting smaller models/architectures representing the huge potential that this field of deep-learning holds. Neural-networks allow us to (good enough)model any arbitrary function/flow using an iterative framework from a few thousand samples representing the function space, effectively equipping us with a very power statistical tool Self-supervised learning don't even need explicit outputs, how cool is that.. See https://ai.meta.com/blog/dino-v2-computer-vision-self-supervised-learning/ this work for more information. to introduce a new independent signal to reduce the entropy of the problem in many domains. I am a fan of smaller personalized models' potential to tackle everyday problems, and myself uses cheap off-the-self cameras coupled with a DL model to detect those Damn Monkeys, and for local voice-synthesis. Monkey Capturing was even on the manifesto of one of the candidates at city-level elections! In country like India, where even (traditional) Automation is limited to products of very few big companies, I can't help smiling whenever i point remote at my "AI" controlled AC :)
Living in a two-tier town in northern India with very minimal fixed-costs has allowed me to work on this for quite a long time without any savings or continuous financial freedom. But i cannot be a hypocrite about it, as it was a conscious decision to learn, explore and implement some of the ideas i had for some time. In return, this has allowed me to stay in touch with friends, played a lot of outdoor games, and help me in reflecting on the things i would want to spend more time in future.
Timely financial grants during the last one and half year from Samagata foundation and FossUnited has allowed me to complete a bulk of work to point, where i am satisfied with the current state of the project, for which i will always be grateful.
I would very much like to continue on this or adjacent projects, as there are still a lot of ideas and code pending, to make it a very stable everyday engine for users to use . But for that i will have to figure out a way to sustain this , without ever compromising the Core features/functionality in any way, As those were some of reasons i started working on it in the first place! Extensions to allow indexing remote storage like Google Drive or Android devices smoothly from the app itself seems like a good direction in that regard for now!